Changelog¶
0.31 (2019-11-11)¶
This version adds compatibility with Python 3.8 and breaks compatibility with Python 3.5.
If you are still running Python 3.5 you should stick with 0.30.2, which you can install like this:
pip install datasette==0.30.2
- Format SQL button now works with read-only SQL queries - thanks, Tobias Kunze (#602)
- New
?column__notin=x,y,zfilter for table views (#614) - Table view now uses
select col1, col2, col3instead ofselect * - Database filenames can now contain spaces - thanks, Tobias Kunze (#590)
- Removed obsolete
?_group_count=colfeature (#504) - Improved user interface and documentation for
datasette publish cloudrun(#608) - Tables with indexes now show the `` CREATE INDEX`` statements on the table page (#618)
- Current version of uvicorn is now shown on
/-/versions - Python 3.8 is now supported! (#622)
- Python 3.5 is no longer supported.
0.30.2 (2019-11-02)¶
/-/pluginspage now uses distribution name e.g.datasette-cluster-mapinstead of the name of the underlying Python package (datasette_cluster_map) (#606)- Array faceting is now only suggested for columns that contain arrays of strings (#562)
- Better documentation for the
--hostargument (#574) - Don’t show
Nonewith a broken link for the label on a nullable foreign key (#406)
0.30.1 (2019-10-30)¶
0.30 (2019-10-18)¶
- Added
/-/threadsdebugging page - Allow
EXPLAIN WITH...(#583) - Button to format SQL - thanks, Tobias Kunze (#136)
- Sort databases on homepage by argument order - thanks, Tobias Kunze (#585)
- Display metadata footer on custom SQL queries - thanks, Tobias Kunze (#589)
- Use
--platform=managedforpublish cloudrun(#587) - Fixed bug returning non-ASCII characters in CSV (#584)
- Fix for
/foov.s./foo-barbug (#601)
0.29.3 (2019-09-02)¶
- Fixed implementation of CodeMirror on database page (#560)
- Documentation typo fixes - thanks, Min ho Kim (#561)
- Mechanism for detecting if a table has FTS enabled now works if the table name used alternative escaping mechanisms (#570) - for compatibility with a recent change to sqlite-utils.
0.29.2 (2019-07-13)¶
0.29.1 (2019-07-11)¶
0.29 (2019-07-07)¶
ASGI, new plugin hooks, facet by date and much, much more…
ASGI¶
ASGI is the Asynchronous Server Gateway Interface standard. I’ve been wanting to convert Datasette into an ASGI application for over a year - Port Datasette to ASGI #272 tracks thirteen months of intermittent development - but with Datasette 0.29 the change is finally released. This also means Datasette now runs on top of Uvicorn and no longer depends on Sanic.
I wrote about the significance of this change in Porting Datasette to ASGI, and Turtles all the way down.
The most exciting consequence of this change is that Datasette plugins can now take advantage of the ASGI standard.
New plugin hook: asgi_wrapper¶
The asgi_wrapper(datasette) plugin hook allows plugins to entirely wrap the Datasette ASGI application in their own ASGI middleware. (#520)
Two new plugins take advantage of this hook:
- datasette-auth-github adds a authentication layer: users will have to sign in using their GitHub account before they can view data or interact with Datasette. You can also use it to restrict access to specific GitHub users, or to members of specified GitHub organizations or teams.
- datasette-cors allows you to configure CORS headers for your Datasette instance. You can use this to enable JavaScript running on a whitelisted set of domains to make
fetch()calls to the JSON API provided by your Datasette instance.
New plugin hook: extra_template_vars¶
The extra_template_vars(template, database, table, view_name, request, datasette) plugin hook allows plugins to inject their own additional variables into the Datasette template context. This can be used in conjunction with custom templates to customize the Datasette interface. datasette-auth-github uses this hook to add custom HTML to the new top navigation bar (which is designed to be modified by plugins, see #540).
Secret plugin configuration options¶
Plugins like datasette-auth-github need a safe way to set secret configuration options. Since the default mechanism for configuring plugins exposes those settings in /-/metadata a new mechanism was needed. Secret configuration values describes how plugins can now specify that their settings should be read from a file or an environment variable:
{
"plugins": {
"datasette-auth-github": {
"client_secret": {
"$env": "GITHUB_CLIENT_SECRET"
}
}
}
}
These plugin secrets can be set directly using datasette publish. See Custom metadata and plugins for details. (#538 and #543)
Facet by date¶
If a column contains datetime values, Datasette can now facet that column by date. (#481)
Easier custom templates for table rows¶
If you want to customize the display of individual table rows, you can do so using a _table.html template include that looks something like this:
{% for row in display_rows %}
<div>
<h2>{{ row["title"] }}</h2>
<p>{{ row["description"] }}<lp>
<p>Category: {{ row.display("category_id") }}</p>
</div>
{% endfor %}
This is a backwards incompatible change. If you previously had a custom template called _rows_and_columns.html you need to rename it to _table.html.
See Custom templates for full details.
?_through= for joins through many-to-many tables¶
The new ?_through={json} argument to the Table view allows records to be filtered based on a many-to-many relationship. See Special table arguments for full documentation - here’s an example. (#355)
This feature was added to help support facet by many-to-many, which isn’t quite ready yet but will be coming in the next Datasette release.
Small changes¶
- Databases published using
datasette publishnow open in Immutable mode. (#469) ?col__date=now works for columns containing spaces- Automatic label detection (for deciding which column to show when linking to a foreign key) has been improved. (#485)
- Fixed bug where pagination broke when combined with an expanded foreign key. (#489)
- Contributors can now run
pip install -e .[docs]to get all of the dependencies needed to build the documentation, includingcd docs && make livehtmlsupport. - Datasette’s dependencies are now all specified using the
~=match operator. (#532) white-space: pre-wrapnow used for table creation SQL. (#505)
Full list of commits between 0.28 and 0.29.
0.28 (2019-05-19)¶
A salmagundi of new features!
Supporting databases that change¶
From the beginning of the project, Datasette has been designed with read-only databases in mind. If a database is guaranteed not to change it opens up all kinds of interesting opportunities - from taking advantage of SQLite immutable mode and HTTP caching to bundling static copies of the database directly in a Docker container. The interesting ideas in Datasette explores this idea in detail.
As my goals for the project have developed, I realized that read-only databases are no longer the right default. SQLite actually supports concurrent access very well provided only one thread attempts to write to a database at a time, and I keep encountering sensible use-cases for running Datasette on top of a database that is processing inserts and updates.
So, as-of version 0.28 Datasette no longer assumes that a database file will not change. It is now safe to point Datasette at a SQLite database which is being updated by another process.
Making this change was a lot of work - see tracking tickets #418, #419 and #420. It required new thinking around how Datasette should calculate table counts (an expensive operation against a large, changing database) and also meant reconsidering the “content hash” URLs Datasette has used in the past to optimize the performance of HTTP caches.
Datasette can still run against immutable files and gains numerous performance benefits from doing so, but this is no longer the default behaviour. Take a look at the new Performance and caching documentation section for details on how to make the most of Datasette against data that you know will be staying read-only and immutable.
Faceting improvements, and faceting plugins¶
Datasette Facets provide an intuitive way to quickly summarize and interact with data. Previously the only supported faceting technique was column faceting, but 0.28 introduces two powerful new capabilities: facet-by-JSON-array and the ability to define further facet types using plugins.
Facet by array (#359) is only available if your SQLite installation provides the json1 extension. Datasette will automatically detect columns that contain JSON arrays of values and offer a faceting interface against those columns - useful for modelling things like tags without needing to break them out into a new table. See Facet by JSON array for more.
The new register_facet_classes() plugin hook (#445) can be used to register additional custom facet classes. Each facet class should provide two methods: suggest() which suggests facet selections that might be appropriate for a provided SQL query, and facet_results() which executes a facet operation and returns results. Datasette’s own faceting implementations have been refactored to use the same API as these plugins.
datasette publish cloudrun¶
Google Cloud Run is a brand new serverless hosting platform from Google, which allows you to build a Docker container which will run only when HTTP traffic is received and will shut down (and hence cost you nothing) the rest of the time. It’s similar to Zeit’s Now v1 Docker hosting platform which sadly is no longer accepting signups from new users.
The new datasette publish cloudrun command was contributed by Romain Primet (#434) and publishes selected databases to a new Datasette instance running on Google Cloud Run.
See Publishing to Google Cloud Run for full documentation.
register_output_renderer plugins¶
Russ Garrett implemented a new Datasette plugin hook called register_output_renderer (#441) which allows plugins to create additional output renderers in addition to Datasette’s default .json and .csv.
Russ’s in-development datasette-geo plugin includes an example of this hook being used to output .geojson automatically converted from SpatiaLite.
Medium changes¶
- Datasette now conforms to the Black coding style (#449) - and has a unit test to enforce this in the future
- New Special table arguments:
?columnname__in=value1,value2,value3filter for executing SQL IN queries against a table, see Table arguments (#433)?columnname__date=yyyy-mm-ddfilter which returns rows where the spoecified datetime column falls on the specified date (583b22a)?tags__arraycontains=tagfilter which acts against a JSON array contained in a column (78e45ea)?_where=sql-fragmentfilter for the table view (#429)?_fts_table=mytableand?_fts_pk=mycolumnquerystring options can be used to specify which FTS table to use for a search query - see Configuring full-text search for a table or view (#428)
- You can now pass the same table filter multiple times - for example,
?content__not=world&content__not=hellowill return all rows where the content column is neitherhelloorworld(#288) - You can now specify
aboutandabout_urlmetadata (in addition tosourceandlicense) linking to further information about a project - see Source, license and about - New
?_trace=1parameter now adds debug information showing every SQL query that was executed while constructing the page (#435) datasette inspectnow just calculates table counts, and does not introspect other database metadata (#462)- Removed
/-/inspectpage entirely - this will be replaced by something similar in the future, see #465 - Datasette can now run against an in-memory SQLite database. You can do this by starting it without passing any files or by using the new
--memoryoption todatasette serve. This can be useful for experimenting with SQLite queries that do not access any data, such asSELECT 1+1orSELECT sqlite_version().
Small changes¶
- We now show the size of the database file next to the download link (#172)
- New
/-/databasesintrospection page shows currently connected databases (#470) - Binary data is no longer displayed on the table and row pages (#442 - thanks, Russ Garrett)
- New show/hide SQL links on custom query pages (#415)
- The extra_body_script plugin hook now accepts an optional
view_nameargument (#443 - thanks, Russ Garrett) - Bumped Jinja2 dependency to 2.10.1 (#426)
- All table filters are now documented, and documentation is enforced via unit tests (2c19a27)
- New project guideline: master should stay shippable at all times! (31f36e1)
- Fixed a bug where
sqlite_timelimit()occasionally failed to clean up after itself (bac4e01) - We no longer load additional plugins when executing pytest (#438)
- Homepage now links to database views if there are less than five tables in a database (#373)
- The
--corsoption is now respected by error pages (#453) datasette publish herokunow uses the--include-vcs-ignoreoption, which means it works under Travis CI (#407)datasette publish herokunow publishes using Python 3.6.8 (666c374)- Renamed
datasette publish nowtodatasette publish nowv1(#472) datasette publish nowv1now accepts multiple--aliasparameters (09ef305)- Removed the
datasette skeletoncommand (#476) - The documentation on how to build the documentation now recommends
sphinx-autobuild
0.27.1 (2019-05-09)¶
- Tiny bugfix release: don’t install
tests/in the wrong place. Thanks, Veit Heller.
0.27 (2019-01-31)¶
- New command:
datasette plugins(documentation) shows you the currently installed list of plugins. - Datasette can now output newline-delimited JSON using the new
?_shape=array&_nl=onquerystring option. - Added documentation on The Datasette Ecosystem.
- Now using Python 3.7.2 as the base for the official Datasette Docker image.
0.26.1 (2019-01-10)¶
/-/versionsnow includes SQLitecompile_options(#396)- datasetteproject/datasette Docker image now uses SQLite 3.26.0 (#397)
- Cleaned up some deprecation warnings under Python 3.7
0.26 (2019-01-02)¶
datasette serve --reloadnow restarts Datasette if a database file changes on disk.datasette publish nownow takes an optional--alias mysite.now.shargument. This will attempt to set an alias after the deploy completes.- Fixed a bug where the advanced CSV export form failed to include the currently selected filters (#393)
0.25.2 (2018-12-16)¶
datasette publish herokunow uses thepython-3.6.7runtime- Added documentation on how to build the documentation
- Added documentation covering our release process
- Upgraded to pytest 4.0.2
0.25.1 (2018-11-04)¶
Documentation improvements plus a fix for publishing to Zeit Now.
datasette publish nownow uses Zeit’s v1 platform, to work around the new 100MB image limit. Thanks, @slygent - closes #366.
0.25 (2018-09-19)¶
New plugin hooks, improved database view support and an easier way to use more recent versions of SQLite.
- New
publish_subcommandplugin hook. A plugin can now add additionaldatasette publishpublishers in addition to the defaultnowandheroku, both of which have been refactored into default plugins. publish_subcommand documentation. Closes #349 - New
render_cellplugin hook. Plugins can now customize how values are displayed in the HTML tables produced by Datasette’s browseable interface. datasette-json-html and datasette-render-images are two new plugins that use this hook. render_cell documentation. Closes #352 - New
extra_body_scriptplugin hook, enabling plugins to provide additional JavaScript that should be added to the page footer. extra_body_script documentation. extra_css_urlsandextra_js_urlshooks now take additional optional parameters, allowing them to be more selective about which pages they apply to. Documentation.- You can now use the sortable_columns metadata setting to explicitly enable sort-by-column in the interface for database views, as well as for specific tables.
- The new
fts_tableandfts_pkmetadata settings can now be used to explicitly configure full-text search for a table or a view, even if that table is not directly coupled to the SQLite FTS feature in the database schema itself. - Datasette will now use pysqlite3 in place of the standard library
sqlite3module if it has been installed in the current environment. This makes it much easier to run Datasette against a more recent version of SQLite, including the just-released SQLite 3.25.0 which adds window function support. More details on how to use this in #360 - New mechanism that allows plugin configuration options to be set using
metadata.json.
0.24 (2018-07-23)¶
A number of small new features:
datasette publish herokunow supports--extra-options, fixes #334- Custom error message if SpatiaLite is needed for specified database, closes #331
- New config option:
truncate_cells_htmlfor truncating long cell values in HTML view - closes #330 - Documentation for datasette publish and datasette package, closes #337
- Fixed compatibility with Python 3.7
datasette publish herokunow supports app names via the-noption, which can also be used to overwrite an existing application [Russ Garrett]- Title and description metadata can now be set for canned SQL queries, closes #342
- New
force_https_onconfig option, fixeshttps://API URLs when deploying to Zeit Now - closes #333 ?_json_infinity=1querystring argument for handling Infinity/-Infinity values in JSON, closes #332- URLs displayed in the results of custom SQL queries are now URLified, closes #298
0.23.2 (2018-07-07)¶
Minor bugfix and documentation release.
- CSV export now respects
--cors, fixes #326 - Installation instructions, including docker image - closes #328
- Fix for row pages for tables with / in, closes #325
0.23.1 (2018-06-21)¶
Minor bugfix release.
- Correctly display empty strings in HTML table, closes #314
- Allow “.” in database filenames, closes #302
- 404s ending in slash redirect to remove that slash, closes #309
- Fixed incorrect display of compound primary keys with foreign key references. Closes #319
- Docs + example of canned SQL query using || concatenation. Closes #321
- Correctly display facets with value of 0 - closes #318
- Default ‘expand labels’ to checked in CSV advanced export
0.23 (2018-06-18)¶
This release features CSV export, improved options for foreign key expansions, new configuration settings and improved support for SpatiaLite.
See datasette/compare/0.22.1…0.23 for a full list of commits added since the last release.
CSV export¶
Any Datasette table, view or custom SQL query can now be exported as CSV.
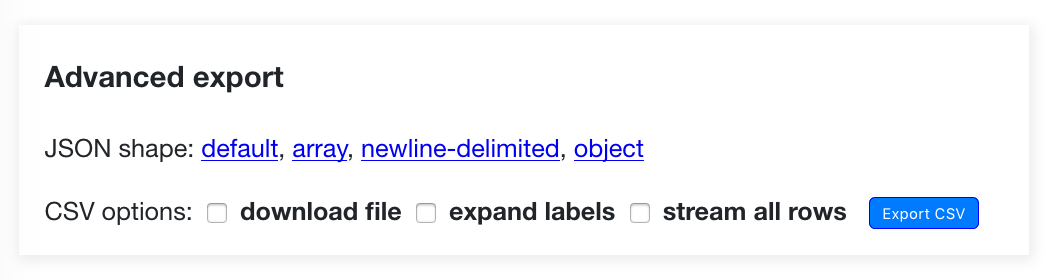
Check out the CSV export documentation for more details, or try the feature out on https://fivethirtyeight.datasettes.com/fivethirtyeight/bechdel%2Fmovies
If your table has more than max_returned_rows (default 1,000) Datasette provides the option to stream all rows. This option takes advantage of async Python and Datasette’s efficient pagination to iterate through the entire matching result set and stream it back as a downloadable CSV file.
Foreign key expansions¶
When Datasette detects a foreign key reference it attempts to resolve a label for that reference (automatically or using the Specifying the label column for a table metadata option) so it can display a link to the associated row.
This expansion is now also available for JSON and CSV representations of the
table, using the new _labels=on querystring option. See
Expanding foreign key references for more details.
New configuration settings¶
Datasette’s Configuration now also supports boolean settings. A number of new configuration options have been added:
num_sql_threads- the number of threads used to execute SQLite queries. Defaults to 3.allow_facet- enable or disable custom Facets using the _facet= parameter. Defaults to on.suggest_facets- should Datasette suggest facets? Defaults to on.allow_download- should users be allowed to download the entire SQLite database? Defaults to on.allow_sql- should users be allowed to execute custom SQL queries? Defaults to on.default_cache_ttl- Default HTTP caching max-age header in seconds. Defaults to 365 days - caching can be disabled entirely by settings this to 0.cache_size_kb- Set the amount of memory SQLite uses for its per-connection cache, in KB.allow_csv_stream- allow users to stream entire result sets as a single CSV file. Defaults to on.max_csv_mb- maximum size of a returned CSV file in MB. Defaults to 100MB, set to 0 to disable this limit.
Control HTTP caching with ?_ttl=¶
You can now customize the HTTP max-age header that is sent on a per-URL basis, using the new ?_ttl= querystring parameter.
You can set this to any value in seconds, or you can set it to 0 to disable HTTP caching entirely.
Consider for example this query which returns a randomly selected member of the Avengers:
select * from [avengers/avengers] order by random() limit 1
If you hit the following page repeatedly you will get the same result, due to HTTP caching:
/fivethirtyeight?sql=select+*+from+%5Bavengers%2Favengers%5D+order+by+random%28%29+limit+1
By adding ?_ttl=0 to the zero you can ensure the page will not be cached and get back a different super hero every time:
/fivethirtyeight?sql=select+*+from+%5Bavengers%2Favengers%5D+order+by+random%28%29+limit+1&_ttl=0
Improved support for SpatiaLite¶
The SpatiaLite module for SQLite adds robust geospatial features to the database.
Getting SpatiaLite working can be tricky, especially if you want to use the most recent alpha version (with support for K-nearest neighbor).
Datasette now includes extensive documentation on SpatiaLite, and thanks to Ravi Kotecha our GitHub repo includes a Dockerfile that can build the latest SpatiaLite and configure it for use with Datasette.
The datasette publish and datasette package commands now accept a new
--spatialite argument which causes them to install and configure SpatiaLite
as part of the container they deploy.
latest.datasette.io¶
Every commit to Datasette master is now automatically deployed by Travis CI to https://latest.datasette.io/ - ensuring there is always a live demo of the latest version of the software.
The demo uses the fixtures from our unit tests, ensuring it demonstrates the same range of functionality that is covered by the tests.
You can see how the deployment mechanism works in our .travis.yml file.
0.22.1 (2018-05-23)¶
Bugfix release, plus we now use versioneer for our version numbers.
Faceting no longer breaks pagination, fixes #282
Add
__version_info__derived from __version__ [Robert Gieseke]This might be tuple of more than two values (major and minor version) if commits have been made after a release.
Add version number support with Versioneer. [Robert Gieseke]
Versioneer Licence: Public Domain (CC0-1.0)
Closes #273
Refactor inspect logic [Russ Garrett]
0.22 (2018-05-20)¶
The big new feature in this release is Facets. Datasette can now apply faceted browse to any column in any table. It will also suggest possible facets. See the Datasette Facets announcement post for more details.
In addition to the work on facets:
New
--configoption, added--help-config, closes #274Removed the
--page_size=argument todatasette servein favour of:datasette serve --config default_page_size:50 mydb.db
Added new help section:
$ datasette --help-config Config options: default_page_size Default page size for the table view (default=100) max_returned_rows Maximum rows that can be returned from a table or custom query (default=1000) sql_time_limit_ms Time limit for a SQL query in milliseconds (default=1000) default_facet_size Number of values to return for requested facets (default=30) facet_time_limit_ms Time limit for calculating a requested facet (default=200) facet_suggest_time_limit_ms Time limit for calculating a suggested facet (default=50)Only apply responsive table styles to
.rows-and-columnOtherwise they interfere with tables in the description, e.g. on https://fivethirtyeight.datasettes.com/fivethirtyeight/nba-elo%2Fnbaallelo
Refactored views into new
views/modules, refs #256Documentation for SQLite full-text search support, closes #253
/-/versionsnow includes SQLitefts_versions, closes #252
0.21 (2018-05-05)¶
New JSON _shape= options, the ability to set table _size= and a mechanism for searching within specific columns.
Default tests to using a longer timelimit
Every now and then a test will fail in Travis CI on Python 3.5 because it hit the default 20ms SQL time limit.
Test fixtures now default to a 200ms time limit, and we only use the 20ms time limit for the specific test that tests query interruption. This should make our tests on Python 3.5 in Travis much more stable.
Support
_search_COLUMN=textsearches, closes #237Show version on
/-/pluginspage, closes #248?_size=maxoption, closes #249Added
/-/versionsand/-/versions.json, closes #244Sample output:
{ "python": { "version": "3.6.3", "full": "3.6.3 (default, Oct 4 2017, 06:09:38) \n[GCC 4.2.1 Compatible Apple LLVM 9.0.0 (clang-900.0.37)]" }, "datasette": { "version": "0.20" }, "sqlite": { "version": "3.23.1", "extensions": { "json1": null, "spatialite": "4.3.0a" } } }
Renamed
?_sql_time_limit_ms=to?_timelimit, closes #242New
?_shape=arrayoption + tweaks to_shape, closes #245- Default is now
?_shape=arrays(renamed fromlists) - New
?_shape=arrayreturns an array of objects as the root object - Changed
?_shape=objectto return the object as the root - Updated docs
- Default is now
FTS tables now detected by
inspect(), closes #240New
?_size=XXXquerystring parameter for table view, closes #229Also added documentation for all of the
_specialarguments.Plus deleted some duplicate logic implementing
_group_count.If
max_returned_rows==page_size, incrementmax_returned_rows- fixes #230New
hidden: Trueoption for table metadata, closes #239Hide
idx_*tables if spatialite detected, closes #228Added
class=rows-and-columnsto custom query results tableAdded CSS class
rows-and-columnsto main tablelabel_columnoption inmetadata.json- closes #234
0.20 (2018-04-20)¶
Mostly new work on the Plugins mechanism: plugins can now bundle static assets and custom templates, and datasette publish has a new --install=name-of-plugin option.
Add col-X classes to HTML table on custom query page
Fixed out-dated template in documentation
Plugins can now bundle custom templates, #224
Added /-/metadata /-/plugins /-/inspect, #225
Documentation for –install option, refs #223
Datasette publish/package –install option, #223
Fix for plugins in Python 3.5, #222
New plugin hooks: extra_css_urls() and extra_js_urls(), #214
/-/static-plugins/PLUGIN_NAME/ now serves static/ from plugins
<th> now gets class=”col-X” - plus added col-X documentation
Use to_css_class for table cell column classes
This ensures that columns with spaces in the name will still generate usable CSS class names. Refs #209
Add column name classes to <td>s, make PK bold [Russ Garrett]
Don’t duplicate simple primary keys in the link column [Russ Garrett]
When there’s a simple (single-column) primary key, it looks weird to duplicate it in the link column.
This change removes the second PK column and treats the link column as if it were the PK column from a header/sorting perspective.
Correct escaping for HTML display of row links [Russ Garrett]
Longer time limit for test_paginate_compound_keys
It was failing intermittently in Travis - see #209
Use application/octet-stream for downloadable databases
Updated PyPI classifiers
Updated PyPI link to pypi.org
0.19 (2018-04-16)¶
This is the first preview of the new Datasette plugins mechanism. Only two plugin hooks are available so far - for custom SQL functions and custom template filters. There’s plenty more to come - read the documentation and get involved in the tracking ticket if you have feedback on the direction so far.
Fix for
_sort_desc=sortable_with_nullstest, refs #216Fixed #216 - paginate correctly when sorting by nullable column
Initial documentation for plugins, closes #213
New
--plugins-dir=plugins/option (#212)New option causing Datasette to load and evaluate all of the Python files in the specified directory and register any plugins that are defined in those files.
This new option is available for the following commands:
datasette serve mydb.db --plugins-dir=plugins/ datasette publish now/heroku mydb.db --plugins-dir=plugins/ datasette package mydb.db --plugins-dir=plugins/
Start of the plugin system, based on pluggy (#210)
Uses https://pluggy.readthedocs.io/ originally created for the py.test project
We’re starting with two plugin hooks:
prepare_connection(conn)This is called when a new SQLite connection is created. It can be used to register custom SQL functions.
prepare_jinja2_environment(env)This is called with the Jinja2 environment. It can be used to register custom template tags and filters.
An example plugin which uses these two hooks can be found at https://github.com/simonw/datasette-plugin-demos or installed using
pip install datasette-plugin-demosRefs #14
Return HTTP 405 on InvalidUsage rather than 500. [Russ Garrett]
This also stops it filling up the logs. This happens for HEAD requests at the moment - which perhaps should be handled better, but that’s a different issue.
0.18 (2018-04-14)¶
This release introduces support for units,
contributed by Russ Garrett (#203).
You can now optionally specify the units for specific columns using metadata.json.
Once specified, units will be displayed in the HTML view of your table. They also become
available for use in filters - if a column is configured with a unit of distance, you can
request all rows where that column is less than 50 meters or more than 20 feet for example.
Link foreign keys which don’t have labels. [Russ Garrett]
This renders unlabeled FKs as simple links.
Also includes bonus fixes for two minor issues:
- In foreign key link hrefs the primary key was escaped using HTML escaping rather than URL escaping. This broke some non-integer PKs.
- Print tracebacks to console when handling 500 errors.
Fix SQLite error when loading rows with no incoming FKs. [Russ Garrett]
This fixes
ERROR: conn=<sqlite3.Connection object at 0x10bbb9f10>, sql = 'select ', params = {'id': '1'}caused by an invalid query when loading incoming FKs.The error was ignored due to async but it still got printed to the console.
Allow custom units to be registered with Pint. [Russ Garrett]
Support units in filters. [Russ Garrett]
Tidy up units support. [Russ Garrett]
- Add units to exported JSON
- Units key in metadata skeleton
- Docs
Initial units support. [Russ Garrett]
Add support for specifying units for a column in
metadata.jsonand rendering them on display using pint
0.17 (2018-04-13)¶
- Release 0.17 to fix issues with PyPI
0.16 (2018-04-13)¶
Better mechanism for handling errors; 404s for missing table/database
New error mechanism closes #193
404s for missing tables/databases closes #184
long_description in markdown for the new PyPI
Hide Spatialite system tables. [Russ Garrett]
Allow
explain select/explain query plan select#201Datasette inspect now finds primary_keys #195
Ability to sort using form fields (for mobile portrait mode) #199
We now display sort options as a select box plus a descending checkbox, which means you can apply sort orders even in portrait mode on a mobile phone where the column headers are hidden.
0.15 (2018-04-09)¶
The biggest new feature in this release is the ability to sort by column. On the
table page the column headers can now be clicked to apply sort (or descending
sort), or you can specify ?_sort=column or ?_sort_desc=column directly
in the URL.
table_rows=>table_rows_count,filtered_table_rows=>filtered_table_rows_countRenamed properties. Closes #194
New
sortable_columnsoption inmetadata.jsonto control sort options.You can now explicitly set which columns in a table can be used for sorting using the
_sortand_sort_descarguments usingmetadata.json:{ "databases": { "database1": { "tables": { "example_table": { "sortable_columns": [ "height", "weight" ] } } } } }
Refs #189
Column headers now link to sort/desc sort - refs #189
_sortand_sort_descparameters for table viewsAllows for paginated sorted results based on a specified column.
Refs #189
Total row count now correct even if
_nextappliedUse .custom_sql() for _group_count implementation (refs #150)
Make HTML title more readable in query template (#180) [Ryan Pitts]
New
?_shape=objects/object/listsparam for JSON API (#192)New
_shape=parameter replacing old.jsonoextensionNow instead of this:
/database/table.jsono
We use the
_shapeparameter like this:/database/table.json?_shape=objects
Also introduced a new
_shapecalledobjectwhich looks like this:/database/table.json?_shape=object
Returning an object for the rows key:
... "rows": { "pk1": { ... }, "pk2": { ... } }
Refs #122
Utility for writing test database fixtures to a .db file
python tests/fixtures.py /tmp/hello.dbThis is useful for making a SQLite database of the test fixtures for interactive exploration.
Compound primary key
_next=now plays well with extra filtersCloses #190
Fixed bug with keyset pagination over compound primary keys
Refs #190
Database/Table views inherit
source/license/source_url/license_urlmetadataIf you set the
source_url/license_url/source/licensefields in your root metadata those values will now be inherited all the way down to the database and table templates.The
title/descriptionare NOT inherited.Also added unit tests for the HTML generated by the metadata.
Refs #185
Add metadata, if it exists, to heroku temp dir (#178) [Tony Hirst]
Initial documentation for pagination
Broke up test_app into test_api and test_html
Fixed bug with .json path regular expression
I had a table called
geojsonand it caused an exception because the regex was matching.jsonand not\.jsonDeploy to Heroku with Python 3.6.3
0.14 (2017-12-09)¶
The theme of this release is customization: Datasette now allows every aspect of its presentation to be customized either using additional CSS or by providing entirely new templates.
Datasette’s metadata.json format
has also been expanded, to allow per-database and per-table metadata. A new
datasette skeleton command can be used to generate a skeleton JSON file
ready to be filled in with per-database and per-table details.
The metadata.json file can also be used to define
canned queries,
as a more powerful alternative to SQL views.
extra_css_urls/extra_js_urlsin metadataA mechanism in the
metadata.jsonformat for adding custom CSS and JS urls.Create a
metadata.jsonfile that looks like this:{ "extra_css_urls": [ "https://simonwillison.net/static/css/all.bf8cd891642c.css" ], "extra_js_urls": [ "https://code.jquery.com/jquery-3.2.1.slim.min.js" ] }
Then start datasette like this:
datasette mydb.db --metadata=metadata.json
The CSS and JavaScript files will be linked in the
<head>of every page.You can also specify a SRI (subresource integrity hash) for these assets:
{ "extra_css_urls": [ { "url": "https://simonwillison.net/static/css/all.bf8cd891642c.css", "sri": "sha384-9qIZekWUyjCyDIf2YK1FRoKiPJq4PHt6tp/ulnuuyRBvazd0hG7pWbE99zvwSznI" } ], "extra_js_urls": [ { "url": "https://code.jquery.com/jquery-3.2.1.slim.min.js", "sri": "sha256-k2WSCIexGzOj3Euiig+TlR8gA0EmPjuc79OEeY5L45g=" } ] }
Modern browsers will only execute the stylesheet or JavaScript if the SRI hash matches the content served. You can generate hashes using https://www.srihash.org/
Auto-link column values that look like URLs (#153)
CSS styling hooks as classes on the body (#153)
Every template now gets CSS classes in the body designed to support custom styling.
The index template (the top level page at
/) gets this:<body class="index">
The database template (
/dbname/) gets this:<body class="db db-dbname">
The table template (
/dbname/tablename) gets:<body class="table db-dbname table-tablename">
The row template (
/dbname/tablename/rowid) gets:<body class="row db-dbname table-tablename">
The
db-xandtable-xclasses use the database or table names themselves IF they are valid CSS identifiers. If they aren’t, we strip any invalid characters out and append a 6 character md5 digest of the original name, in order to ensure that multiple tables which resolve to the same stripped character version still have different CSS classes.Some examples (extracted from the unit tests):
"simple" => "simple" "MixedCase" => "MixedCase" "-no-leading-hyphens" => "no-leading-hyphens-65bea6" "_no-leading-underscores" => "no-leading-underscores-b921bc" "no spaces" => "no-spaces-7088d7" "-" => "336d5e" "no $ characters" => "no--characters-59e024"
datasette --template-dir=mytemplates/argumentYou can now pass an additional argument specifying a directory to look for custom templates in.
Datasette will fall back on the default templates if a template is not found in that directory.
Ability to over-ride templates for individual tables/databases.
It is now possible to over-ride templates on a per-database / per-row or per- table basis.
When you access e.g.
/mydatabase/mytableDatasette will look for the following:- table-mydatabase-mytable.html - table.html
If you provided a
--template-dirargument to datasette serve it will look in that directory first.The lookup rules are as follows:
Index page (/): index.html Database page (/mydatabase): database-mydatabase.html database.html Table page (/mydatabase/mytable): table-mydatabase-mytable.html table.html Row page (/mydatabase/mytable/id): row-mydatabase-mytable.html row.html
If a table name has spaces or other unexpected characters in it, the template filename will follow the same rules as our custom
<body>CSS classes - for example, a table called “Food Trucks” will attempt to load the following templates:table-mydatabase-Food-Trucks-399138.html table.html
It is possible to extend the default templates using Jinja template inheritance. If you want to customize EVERY row template with some additional content you can do so by creating a row.html template like this:
{% extends "default:row.html" %} {% block content %} <h1>EXTRA HTML AT THE TOP OF THE CONTENT BLOCK</h1> <p>This line renders the original block:</p> {{ super() }} {% endblock %}
--staticoption for datasette serve (#160)You can now tell Datasette to serve static files from a specific location at a specific mountpoint.
For example:
datasette serve mydb.db --static extra-css:/tmp/static/css
Now if you visit this URL:
http://localhost:8001/extra-css/blah.css
The following file will be served:
/tmp/static/css/blah.css
Canned query support.
Named canned queries can now be defined in
metadata.jsonlike this:{ "databases": { "timezones": { "queries": { "timezone_for_point": "select tzid from timezones ..." } } } }
These will be shown in a new “Queries” section beneath “Views” on the database page.
New
datasette skeletoncommand for generatingmetadata.json(#164)metadata.jsonsupport for per-table/per-database metadata (#165)Also added support for descriptions and HTML descriptions.
Here’s an example metadata.json file illustrating custom per-database and per- table metadata:
{ "title": "Overall datasette title", "description_html": "This is a <em>description with HTML</em>.", "databases": { "db1": { "title": "First database", "description": "This is a string description & has no HTML", "license_url": "http://example.com/", "license": "The example license", "queries": { "canned_query": "select * from table1 limit 3;" }, "tables": { "table1": { "title": "Custom title for table1", "description": "Tables can have descriptions too", "source": "This has a custom source", "source_url": "http://example.com/" } } } } }
Renamed
datasette buildcommand todatasette inspect(#130)Upgrade to Sanic 0.7.0 (#168)
Package and publish commands now accept
--staticand--template-dirExample usage:
datasette package --static css:extra-css/ --static js:extra-js/ \ sf-trees.db --template-dir templates/ --tag sf-trees --branch master
This creates a local Docker image that includes copies of the templates/, extra-css/ and extra-js/ directories. You can then run it like this:
docker run -p 8001:8001 sf-trees
For publishing to Zeit now:
datasette publish now --static css:extra-css/ --static js:extra-js/ \ sf-trees.db --template-dir templates/ --name sf-trees --branch master
HTML comment showing which templates were considered for a page (#171)
0.13 (2017-11-24)¶
Search now applies to current filters.
Combined search into the same form as filters.
Closes #133
Much tidier design for table view header.
Closes #147
Added
?column__not=blahfilter.Closes #148
Row page now resolves foreign keys.
Closes #132
Further tweaks to select/input filter styling.
Refs #86 - thanks for the help, @natbat!
Show linked foreign key in table cells.
Added UI for editing table filters.
Refs #86
Hide FTS-created tables on index pages.
Closes #129
Add publish to heroku support [Jacob Kaplan-Moss]
datasette publish heroku mydb.dbPull request #104
Initial implementation of
?_group_count=column.URL shortcut for counting rows grouped by one or more columns.
?_group_count=column1&_group_count=column2works as well.SQL generated looks like this:
select "qSpecies", count(*) as "count" from Street_Tree_List group by "qSpecies" order by "count" desc limit 100
Or for two columns like this:
select "qSpecies", "qSiteInfo", count(*) as "count" from Street_Tree_List group by "qSpecies", "qSiteInfo" order by "count" desc limit 100
Refs #44
Added
--build=masteroption to datasette publish and package.The
datasette publishanddatasette packagecommands both now accept an optional--buildargument. If provided, this can be used to specify a branch published to GitHub that should be built into the container.This makes it easier to test code that has not yet been officially released to PyPI, e.g.:
datasette publish now mydb.db --branch=master
Implemented
?_search=XXX+ UI if a FTS table is detected.Closes #131
Added
datasette --versionsupport.Table views now show expanded foreign key references, if possible.
If a table has foreign key columns, and those foreign key tables have
label_columns, the TableView will now query those other tables for the corresponding values and display those values as links in the corresponding table cells.label_columns are currently detected by the
inspect()function, which looks for any table that has just two columns - an ID column and one other - and sets thelabel_columnto be that second non-ID column.Don’t prevent tabbing to “Run SQL” button (#117) [Robert Gieseke]
See comment in #115
Add keyboard shortcut to execute SQL query (#115) [Robert Gieseke]
Allow
--load-extensionto be set via environment variable.Add support for
?field__isnull=1(#107) [Ray N]Add spatialite, switch to debian and local build (#114) [Ariel Núñez]
Added
--load-extensionargument to datasette serve.Allows loading of SQLite extensions. Refs #110.
0.12 (2017-11-16)¶
Added
__version__, now displayed as tooltip in page footer (#108).Added initial docs, including a changelog (#99).
Turned on auto-escaping in Jinja.
Added a UI for editing named parameters (#96).
You can now construct a custom SQL statement using SQLite named parameters (e.g.
:name) and datasette will display form fields for editing those parameters. Here’s an example which lets you see the most popular names for dogs of different species registered through various dog registration schemes in Australia.
Pin to specific Jinja version. (#100).
Default to 127.0.0.1 not 0.0.0.0. (#98).
Added extra metadata options to publish and package commands. (#92).
You can now run these commands like so:
datasette now publish mydb.db \ --title="My Title" \ --source="Source" \ --source_url="http://www.example.com/" \ --license="CC0" \ --license_url="https://creativecommons.org/publicdomain/zero/1.0/"
This will write those values into the metadata.json that is packaged with the app. If you also pass
--metadata=metadata.jsonthat file will be updated with the extra values before being written into the Docker image.Added simple production-ready Dockerfile (#94) [Andrew Cutler]
New
?_sql_time_limit_ms=10argument to database and table page (#95)SQL syntax highlighting with Codemirror (#89) [Tom Dyson]
0.11 (2017-11-14)¶
Added
datasette publish now --forceoption.This calls
nowwith--force- useful as it means you get a fresh copy of datasette even if Now has already cached that docker layer.Enable
--corsby default when running in a container.
0.10 (2017-11-14)¶
Fixed #83 - 500 error on individual row pages.
Stop using sqlite WITH RECURSIVE in our tests.
The version of Python 3 running in Travis CI doesn’t support this.
0.9 (2017-11-13)¶
Added
--sql_time_limit_msand--extra-options.The serve command now accepts
--sql_time_limit_msfor customizing the SQL time limit.The publish and package commands now accept
--extra-optionswhich can be used to specify additional options to be passed to the datasite serve command when it executes inside the resulting Docker containers.
0.8 (2017-11-13)¶
V0.8 - added PyPI metadata, ready to ship.
Implemented offset/limit pagination for views (#70).
Improved pagination. (#78)
Limit on max rows returned, controlled by
--max_returned_rowsoption. (#69)If someone executes ‘select * from table’ against a table with a million rows in it, we could run into problems: just serializing that much data as JSON is likely to lock up the server.
Solution: we now have a hard limit on the maximum number of rows that can be returned by a query. If that limit is exceeded, the server will return a
"truncated": truefield in the JSON.This limit can be optionally controlled by the new
--max_returned_rowsoption. Setting that option to 0 disables the limit entirely.